![]()

sktime 介绍#
愿景声明#
一个易于使用、易于扩展、全面的面向时间序列机器学习和人工智能的 Python 框架
开源、许可宽松、免费使用
公开透明地治理
友好、响应迅速、友善和包容的社区,积极致力于确保公平和机会均等
一个学术上和商业上中立的空间,具有生态系统集成的愿景和中立的视角
一个教育平台,为所有职业阶段,特别是早期职业人士提供指导和技能提升机会
sktime 是一个充满活力、热烈欢迎新人的社区,提供指导机会!
延伸阅读
sktimebinder 上的 notebook 教程录制好的视频教程
发现 bug 或问题? 教程反馈帖
目录#
sktime 提供了一个统一的、类似于 scikit-learn 的工具箱接口,用于处理多种时间序列学习任务。
第 1 节 使用 scikit-learn 作为示例,解释了什么是类似于 scikit-learn 的工具箱。
第 2 节 概述了时间序列学习及其领域的挑战。
第 3 节 提供了 sktime 的高级工程概览。
1. sklearn 统一接口 - 策略模式#
sktime 遵循 sklearn / skbase 接口
统一的对象/评估器接口
模块化设计,策略模式
可组合,组合体接口一致
简单的规范语言和参数接口
可视化丰富的漂亮打印输出
sklearn 提供了一个统一接口,用于多种学习任务,包括分类和回归。
任何(监督)评估器都具有以下接口点
通过参数设置实例化您选择的模型
拟合您的模型实例
使用该已拟合实例来预测新数据!
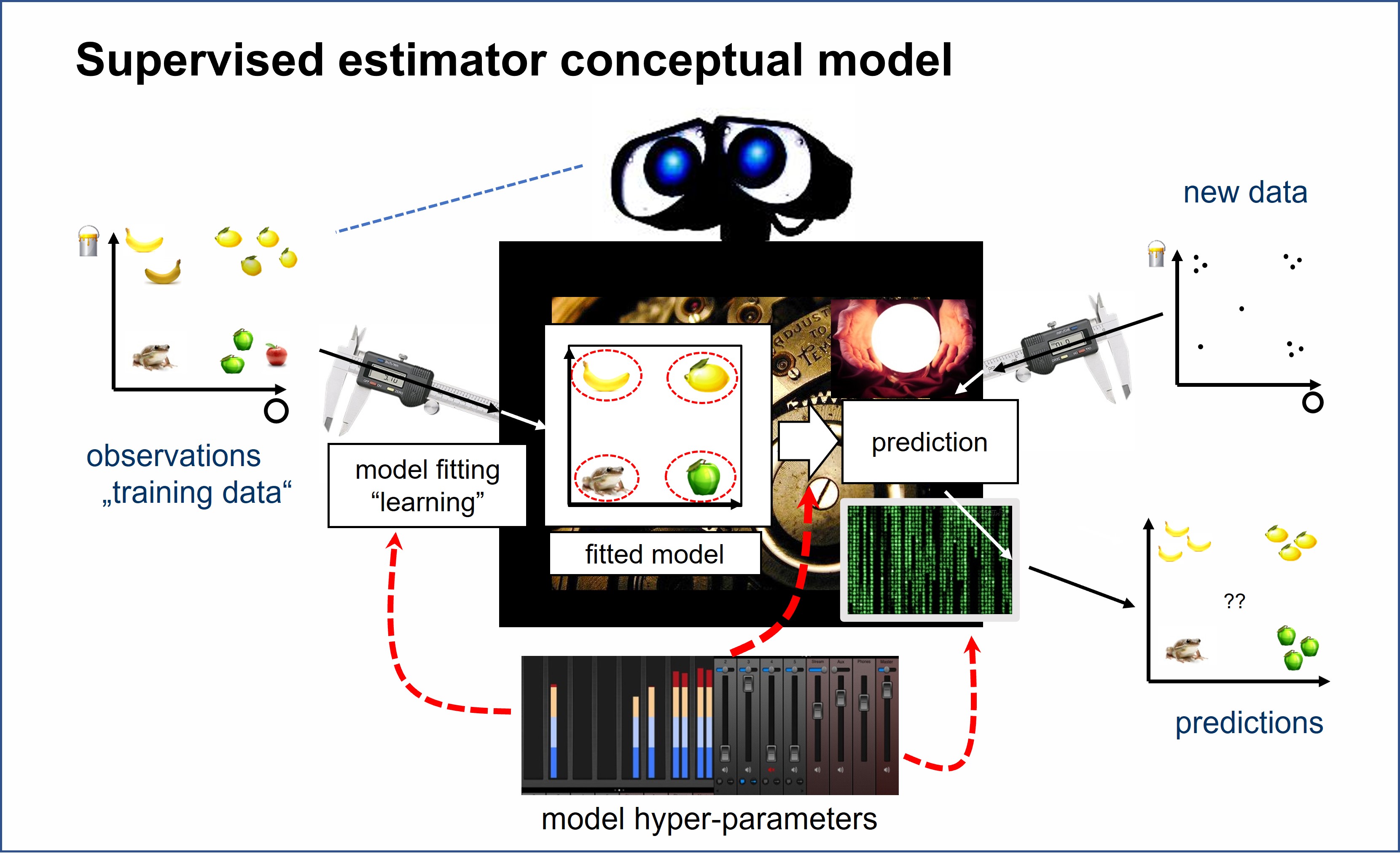
上述代码示例
[1]:
import warnings
warnings.filterwarnings("ignore")
[2]:
# get data to use the model on
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X, y = load_iris(return_X_y=True, as_frame=True)
random_seed = 60
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=random_seed)
[3]:
X_train.head()
[3]:
| 萼片长度 (cm) | 萼片宽度 (cm) | 花瓣长度 (cm) | 花瓣宽度 (cm) | |
|---|---|---|---|---|
| 59 | 5.2 | 2.7 | 3.9 | 1.4 |
| 52 | 6.9 | 3.1 | 4.9 | 1.5 |
| 108 | 6.7 | 2.5 | 5.8 | 1.8 |
| 36 | 5.5 | 3.5 | 1.3 | 0.2 |
| 134 | 6.1 | 2.6 | 5.6 | 1.4 |
[4]:
y_train.head()
[4]:
59 1
52 1
108 2
36 0
134 2
Name: target, dtype: int64
[5]:
X_test.head()
[5]:
| 萼片长度 (cm) | 萼片宽度 (cm) | 花瓣长度 (cm) | 花瓣宽度 (cm) | |
|---|---|---|---|---|
| 69 | 5.6 | 2.5 | 3.9 | 1.1 |
| 71 | 6.1 | 2.8 | 4.0 | 1.3 |
| 97 | 6.2 | 2.9 | 4.3 | 1.3 |
| 42 | 4.4 | 3.2 | 1.3 | 0.2 |
| 73 | 6.1 | 2.8 | 4.7 | 1.2 |
[6]:
from sklearn.svm import SVC
# 1. Instantiate SVC with parameters gamma, C
clf = SVC(gamma=0.001, C=100.0)
# 2. Fit clf to training data
clf.fit(X_train, y_train)
# 3. Predict labels on test data
y_test_pred = clf.predict(X_test)
y_test_pred
[6]:
array([1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 2, 1, 2, 1, 2, 1, 0, 2, 2, 0,
1, 0, 0, 0, 0, 1, 2, 0, 2, 1, 2, 0, 0, 0, 1, 0])
重要提示:要使用另一个分类器,只需要更改规范行的第 1 部分!
SVC 可以换成 RandomForest,步骤 2 和 3 保持不变 - 统一接口
[7]:
from sklearn.ensemble import RandomForestClassifier
# 1. Instantiate SVC with parameters gamma, C
clf = RandomForestClassifier(n_estimators=100)
# 2. Fit clf to training data
clf.fit(X_train, y_train)
# 3. Predict labels on test data
y_test_pred = clf.predict(X_test)
y_test_pred
[7]:
array([1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 2, 1, 2, 1, 2, 1, 0, 2, 2, 0,
1, 0, 0, 0, 0, 1, 2, 0, 2, 1, 2, 0, 0, 0, 1, 0])
在面向对象设计术语中,这称为“策略模式”
= 不同的评估器可以切换使用,而无需更改接口
= 就像电源插头适配器一样,如果符合接口,就可以即插即用
图示总结

参数可以通过 get_params, set_params 访问和设置
[8]:
clf.get_params()
[8]:
{'bootstrap': True,
'ccp_alpha': 0.0,
'class_weight': None,
'criterion': 'gini',
'max_depth': None,
'max_features': 'sqrt',
'max_leaf_nodes': None,
'max_samples': None,
'min_impurity_decrease': 0.0,
'min_samples_leaf': 1,
'min_samples_split': 2,
'min_weight_fraction_leaf': 0.0,
'monotonic_cst': None,
'n_estimators': 100,
'n_jobs': None,
'oob_score': False,
'random_state': None,
'verbose': 0,
'warm_start': False}
2. sktime 专注于时间序列数据分析#
与“表格”数据相比,时间序列任务领域更丰富
预测 (Forecasting) - 根据过去几周的数据预测明天的能源消耗
分类 (Classification) - 根据先前的示例将心电图分类为健康/患病
回归 (Regression) - 根据温度/压力曲线预测生物反应器中化合物的纯度
聚类 (Clustering) - 将树叶轮廓分为少量相似类别
标注 (Annotation) - 识别数据流中的跳跃、异常、事件
sktime 旨在为这些任务提供类似于 sklearn 的、模块化的、可组合的接口!
任务 |
状态 |
链接 |
|---|---|---|
预测 |
稳定 |
|
时间序列分类 |
稳定 |
|
时间序列回归 |
稳定 |
|
转换 |
稳定 |
|
预测性能指标 |
稳定 |
|
时间序列拆分/重采样 |
稳定 |
|
参数拟合 |
成熟中 |
|
时间序列对齐 |
成熟中 |
|
时间序列聚类 |
成熟中 |
|
时间序列距离/核函数 |
成熟中 |
|
异常、变化点 |
实验性 |
在 skpro 伴侣包中
示例 - 预测#
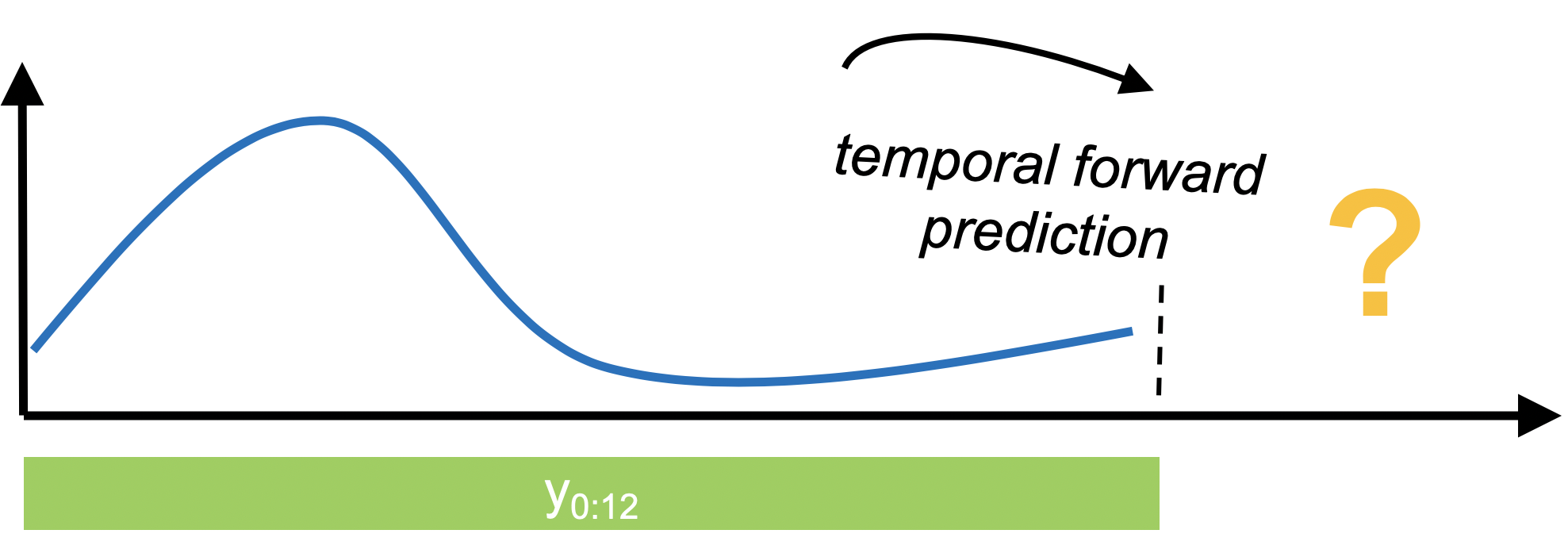
[ ]:
# get the data
from sktime.datasets import load_airline
y = load_airline()
[9]:
import numpy as np
from sktime.forecasting.naive import NaiveForecaster
# step 1: specify the forecasting algorithm
forecaster = NaiveForecaster(strategy="last", sp=12)
# step 2: specify forecasting horizon
fh = np.arange(1, 37) # we want to predict the next 36 months
# step 3: fit the forecaster
forecaster.fit(y, fh=fh)
# step 4: make the forecast
y_pred = forecaster.predict()
[10]:
from sktime.utils.plotting import plot_series
fig, ax = plot_series(y, y_pred, labels=["train", "forecast"])
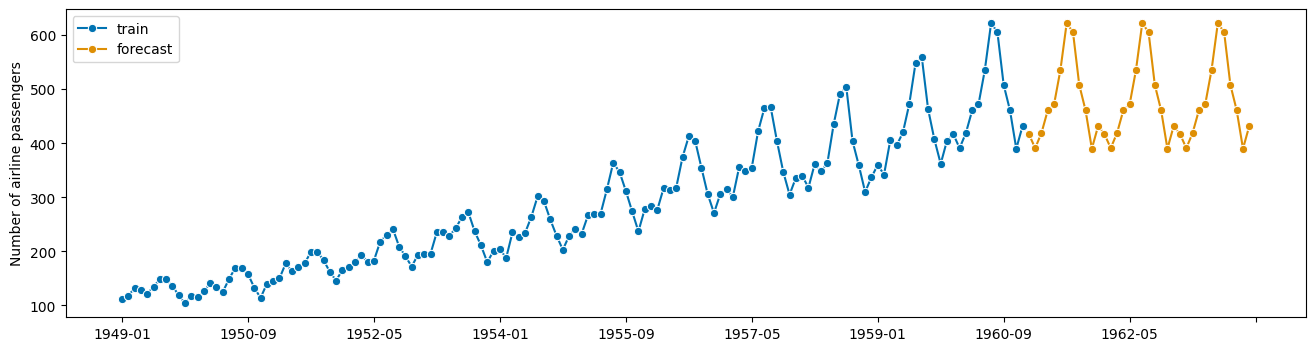
示例 - 时间序列分类#
[ ]:
# get the data
from sktime.datasets import load_osuleaf
# for training
X_train, y_train = load_osuleaf(split="train", return_type="numpy3D")
# for prediction
X_new, _ = load_osuleaf(split="test", return_type="numpy3D")
X_new = X_new[:2]
[11]:
from sktime.classification.distance_based import KNeighborsTimeSeriesClassifier
from sktime.dists_kernels import ScipyDist
from sktime.dists_kernels.compose_tab_to_panel import AggrDist
# step 1 - specify the classifier
mean_eucl_dist = AggrDist(ScipyDist())
clf = KNeighborsTimeSeriesClassifier(n_neighbors=3, distance=mean_eucl_dist)
# step 2 - fit the classifier
clf.fit(X_train, y_train)
# step 3 - predict labels on new data
y_pred = clf.predict(X_new)
[12]:
X_train.shape
[12]:
(200, 1, 427)
[13]:
y_train.shape
[13]:
(200,)
[14]:
X_new.shape
[14]:
(2, 1, 427)
[15]:
y_pred.shape
[15]:
(2,)
3. sktime 集成了时间序列建模生态系统!#
时间序列的包空间高度碎片化
有很多出色的实现和方法!
但是接口各不相同,不像
sklearn那样可组合
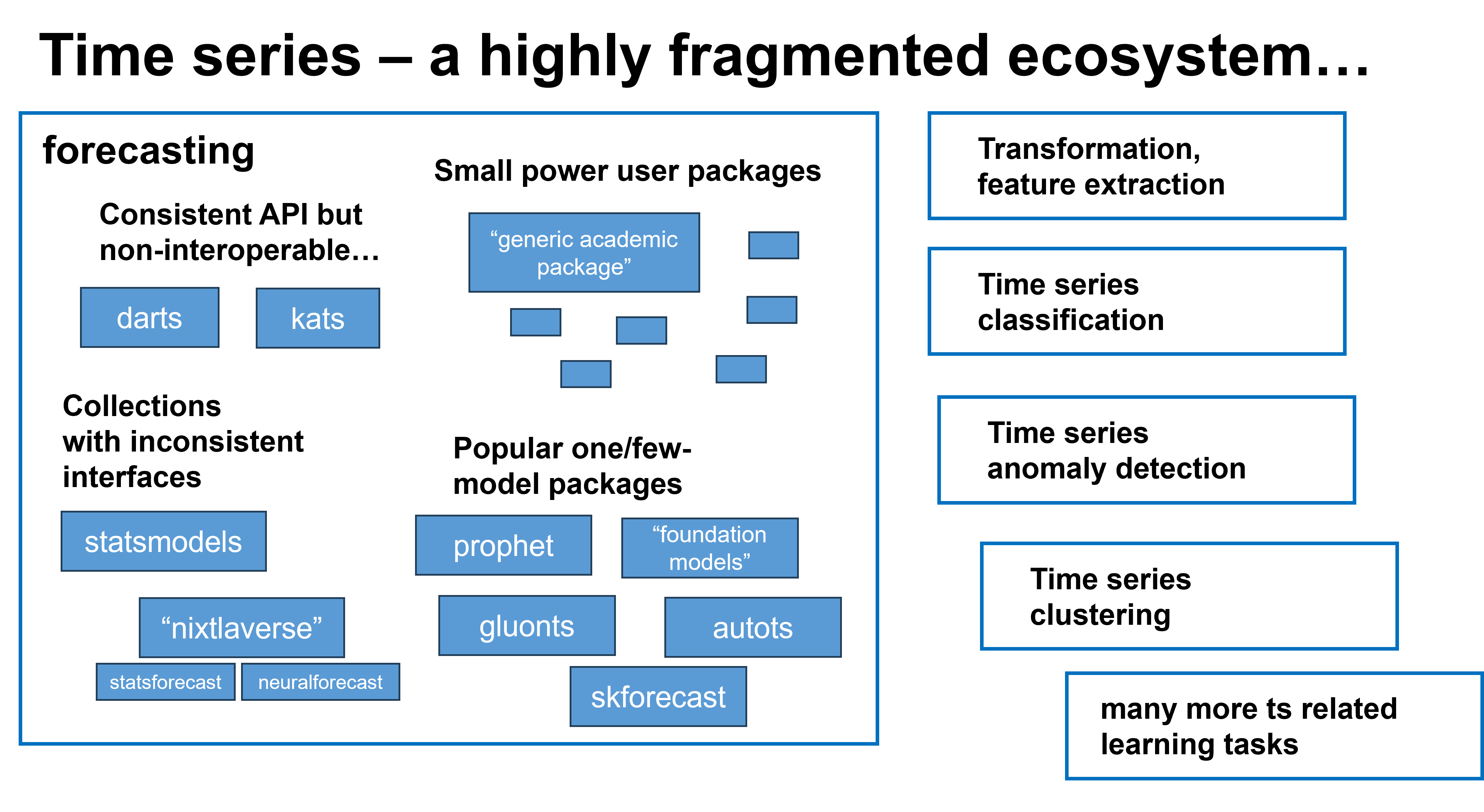
sktime 集成了生态系统 - 与所有现有的包友好协作!
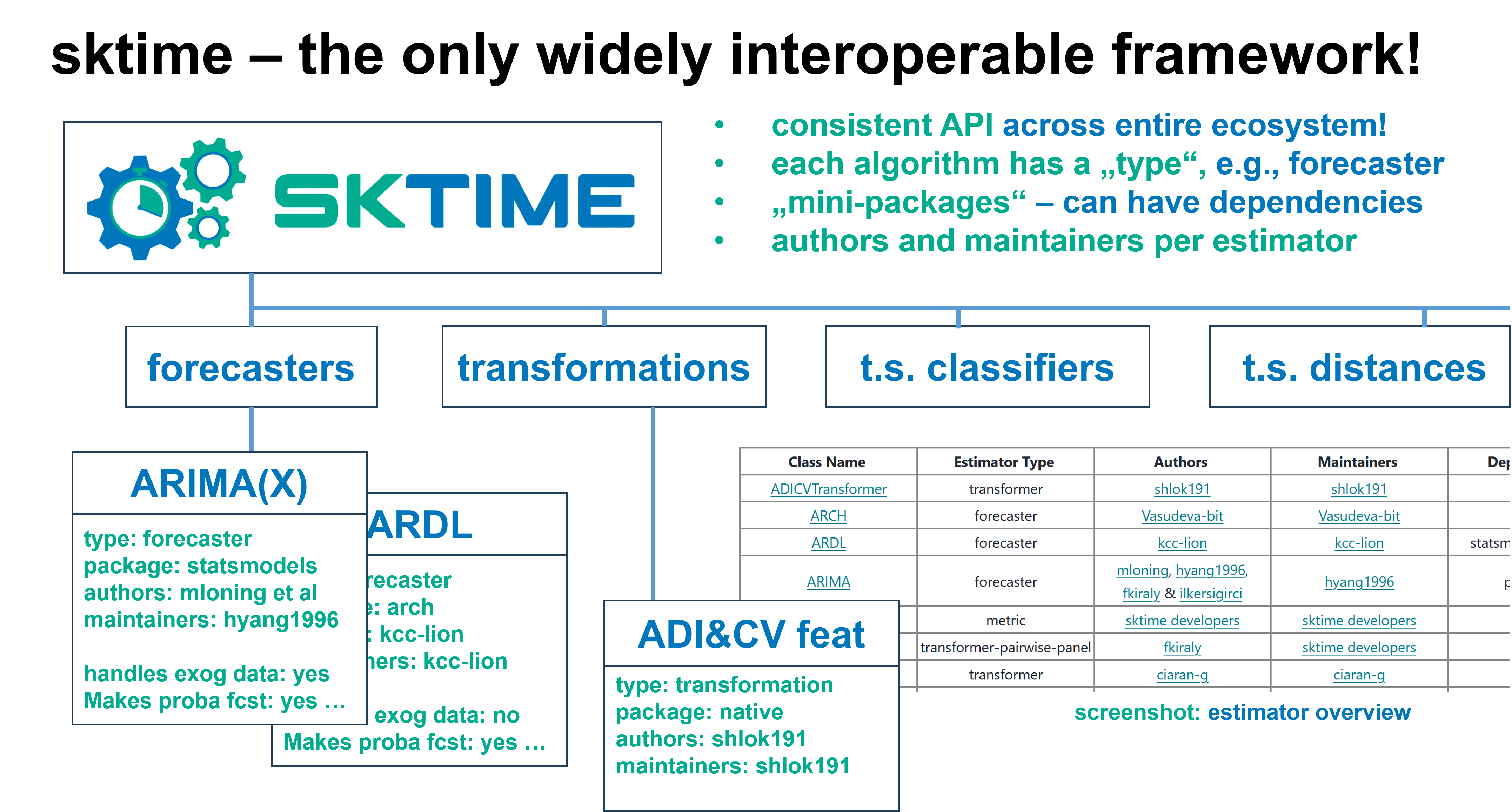
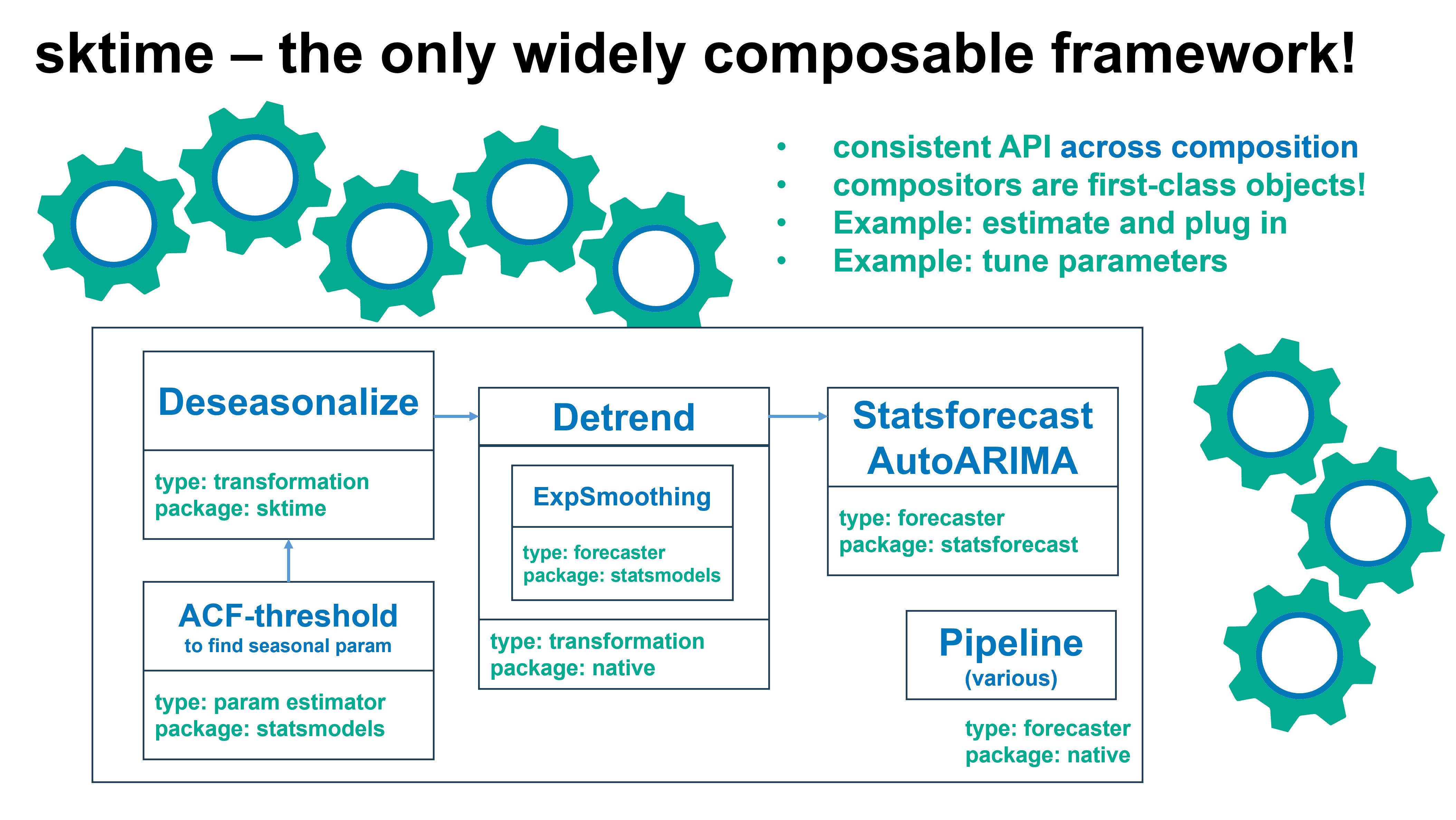
轻松搜索生态系统中的即插即用组件!
试试 `sktime 评估器搜索 <https://sktime.net.cn/en/stable/estimator_overview.html>`__

4. 总结#
sklearn接口:统一接口(策略模式)、模块化、组合稳定、简单的规范语言sktime发展了时间序列学习任务的接口sktime通过接口、可组合性和依赖管理集成了碎片化的生态系统
致谢:notebook 0 - sktime 和 sklearn 介绍#
notebook 创建者:fkiraly, marrov
部分小节基于现有的 sktime 教程,致谢:fkiraly, miraep8
幻灯片 (png/jpg)
摘自 fkiraly 在 UCL 的研究生课程《数据科学软件工程的原理与模式》
生态系统幻灯片:fkiraly, mloning
学习任务:fkiraly, mloning
学术研究论文中的引用和致谢
sktime 工具箱:sktime: 一个用于时间序列机器学习的统一接口
sktime 设计原则:设计机器学习工具箱:概念、原理与模式